python -m predictions.batch_predictions uptrend
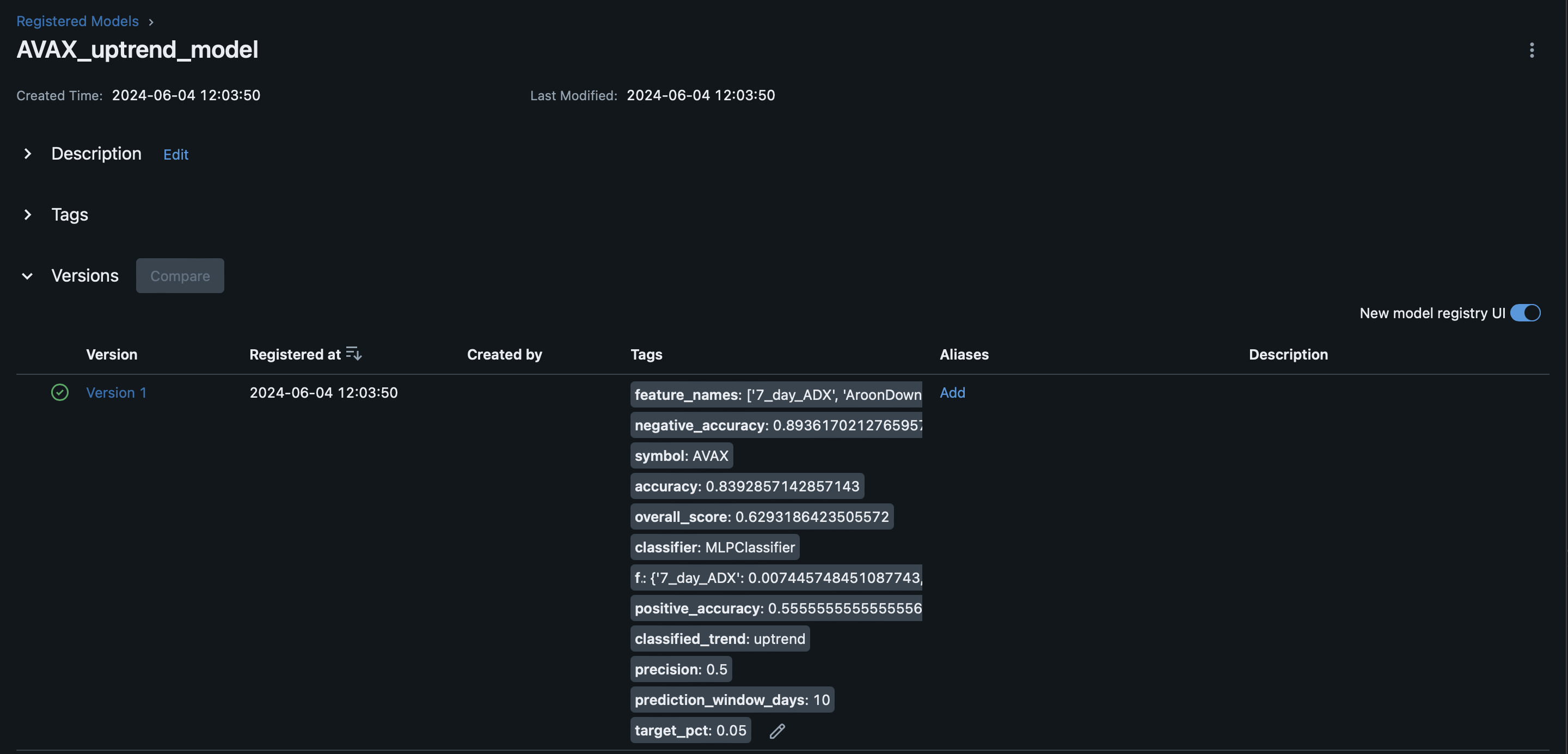
Prediction(symbol='AVAX', prediction=0.08797024112491493, tags=ModelTags(positive_accuracy='0.5555555555555556', negative_accuracy='0.8936170212765957', overall_score='0.6293186423505572', accuracy='0.8392857142857143', precision='0.5', symbol='AVAX', classifier='MLPClassifier', classified_trend='uptrend', target_pct='0.05', prediction_window_days='10', feature_names="['7_day_ADX', 'AroonDown', 'AroonUp', 'MACD', 'MACD_Signal', 'MACD_Hist', '7_day_RSI', 'SlowK', 'SlowD', '7_day_MFI', '7_day_DX', '7_day_TRIX', 'PPO', 'OBV_pct_change', 'AD_pct_change', 'BBANDS_distance_pct', '2_day_SMA_10_day_SMA_pct_diff', '2_day_SMA_20_day_SMA_pct_diff', '10_day_SMA_20_day_SMA_pct_diff']", feature_importance="{'7_day_ADX': 0.007445748451087743, 'AroonDown': -0.03420282474310941, 'AroonUp': -0.006806365934893178, 'MACD': 0.009851930090292742, 'MACD_Signal': 0.01872037634072151, 'MACD_Hist': -0.00038134231684378337, '7_day_RSI': -0.00447165026146559, 'SlowK': 0.0057498121581468515, 'SlowD': -0.012869322604550324, '7_day_MFI': 0.01109616869923093, '7_day_DX': 0.008746157567726159, '7_day_TRIX': -0.09396269471943668, 'PPO': -0.022627486901161814, 'OBV_pct_change': -0.006502963995860393, 'AD_pct_change': -0.007990124555058938, 'BBANDS_distance_pct': 0.005792011465134371, '2_day_SMA_10_day_SMA_pct_diff': -0.037850639901746794, '2_day_SMA_20_day_SMA_pct_diff': 0.0754213434764908, '10_day_SMA_20_day_SMA_pct_diff': 0.04341329625672436}"))
--------------------------
Prediction(symbol='BCH', prediction=0.5242774257331716, tags=ModelTags(positive_accuracy='0.6428571428571429', negative_accuracy='0.9545454545454546', overall_score='0.7989699955217198', accuracy='0.8793103448275862', precision='0.8181818181818182', symbol='BCH', classifier='MLPClassifier', classified_trend='uptrend', target_pct='0.05', prediction_window_days='10', feature_names="['7_day_ADX', 'AroonDown', 'AroonUp', 'MACD', 'MACD_Signal', 'MACD_Hist', '7_day_RSI', 'SlowK', 'SlowD', '7_day_MFI', '7_day_DX', '7_day_TRIX', 'PPO', 'OBV_pct_change', 'AD_pct_change', 'BBANDS_distance_pct', '2_day_SMA_10_day_SMA_pct_diff', '2_day_SMA_20_day_SMA_pct_diff', '10_day_SMA_20_day_SMA_pct_diff']", feature_importance="{'7_day_ADX': -0.011434522711156974, 'AroonDown': 0.0034590618165668933, 'AroonUp': 0.00036602358400324565, 'MACD': -0.0019961766024331968, 'MACD_Signal': -0.0402090192861234, 'MACD_Hist': -0.020724063948034027, '7_day_RSI': -0.0012447167585948715, 'SlowK': 0.0013838787305832333, 'SlowD': 0.003059973207332214, '7_day_MFI': -0.006375397144073281, '7_day_DX': 0.002475381276557034, '7_day_TRIX': 0.018376494677847424, 'PPO': -0.010871152759239108, 'OBV_pct_change': 0.0017858697031143515, 'AD_pct_change': 0.00032245040005649174, 'BBANDS_distance_pct': -0.015327945788925624, '2_day_SMA_10_day_SMA_pct_diff': 0.009938639667201942, '2_day_SMA_20_day_SMA_pct_diff': 0.005847329537153156, '10_day_SMA_20_day_SMA_pct_diff': 0.02582306481195758}"))
--------------------------
Prediction(symbol='GRT', prediction=0, tags=ModelTags(positive_accuracy='0.8095238095238095', negative_accuracy='0.7777777777777778', overall_score='0.7493600668337511', accuracy='0.7894736842105263', precision='0.68', symbol='GRT', classifier='RidgeClassifier', classified_trend='uptrend', target_pct='0.05', prediction_window_days='10', feature_names="['7_day_ADX', 'AroonDown', 'AroonUp', 'MACD', 'MACD_Signal', 'MACD_Hist', '7_day_RSI', 'SlowK', 'SlowD', '7_day_MFI', '7_day_DX', '7_day_TRIX', 'PPO', 'OBV_pct_change', 'AD_pct_change', 'BBANDS_distance_pct', '2_day_SMA_10_day_SMA_pct_diff', '2_day_SMA_20_day_SMA_pct_diff', '10_day_SMA_20_day_SMA_pct_diff']", feature_importance="{'7_day_ADX': -0.004653367573063757, 'AroonDown': 0.00543810871267663, 'AroonUp': 0.01081495407838227, 'MACD': -0.00043034328831368453, 'MACD_Signal': 0.0007199178505146046, 'MACD_Hist': 6.171883375290897e-05, '7_day_RSI': 0.021678857731158806, 'SlowK': 0.025011955969490348, 'SlowD': -0.008690773448199672, '7_day_MFI': -0.006178877454886704, '7_day_DX': 0.0023309299936438866, '7_day_TRIX': -0.015204482187342777, 'PPO': 0.04873721704289985, 'OBV_pct_change': 0.00015699279263542158, 'AD_pct_change': -8.033011573586306e-05, 'BBANDS_distance_pct': -0.00245956447445686, '2_day_SMA_10_day_SMA_pct_diff': 0.003682598406320119, '2_day_SMA_20_day_SMA_pct_diff': 0.0029241021973484007, '10_day_SMA_20_day_SMA_pct_diff': 0.014736876161246266}"))
--------------------------

Comments